This is a brief summary of the paper by Wadia at el. from the Rutishauser and Tsao labs that I presented at Gatsby TNJC. My slides are here.
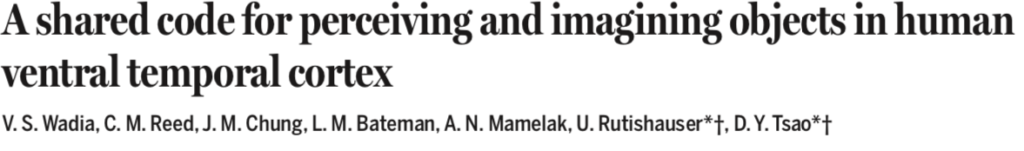
Does the same circuitry get activated when we view an object as when we imagine it? Does the human visual system contain a generative model for images? In this paper, the authors use single unit recordings from human ventral temporal cortex (VTC) to find out!
The VTC is an area deep in the visual stream that is involved in processing faces and objects. Epilepsy patients can have electrodes implanted in this area to monitor their condition in hospital. Such monitoring is quite boring and patients are often willing to participate in neuroscience experiments. This gives neuroscientists a unique opportunity to record from an awake human brain while interacting with it, allowing experiments that would otherwise be impossible.

In the present set of experiments, the authors had ~60 participants look at 500 different images while neural activity in VTC was recorded. The collected the responses of a total of ~750 neurons over 16 sessions. The authors found that the majority of neurons in the VTC are selective to visual categories.
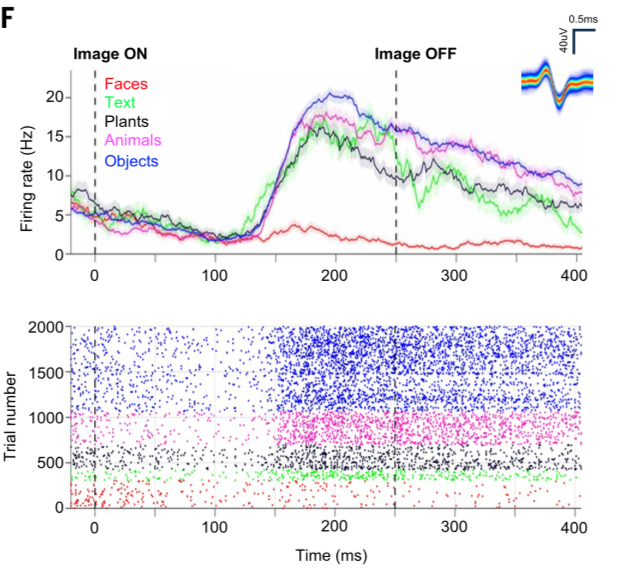
Interestingly, when they examined the way their neurons responded to images, they found that 80% used an “axis”-code, a linear weighting of high-level image features. That is, $$ r|\ff \approx \cc_\text{pref}^T \ff + c_0,$$ where $\ff$ are the features of an image, and the coefficients are learned per neuron by least squares.
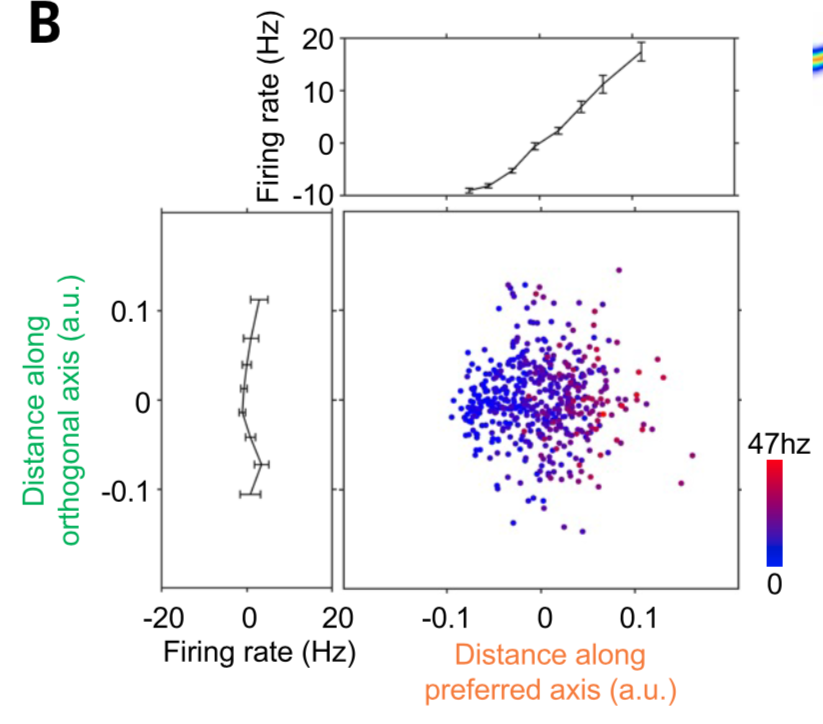
They generated the basis features from the first fully connected layer of AlexNet, though the results generalized to other deep nets for visual processing. Their axis code beat category coding and exemplar coding, two other plausible models of neural responses, in explaining the neural responses.
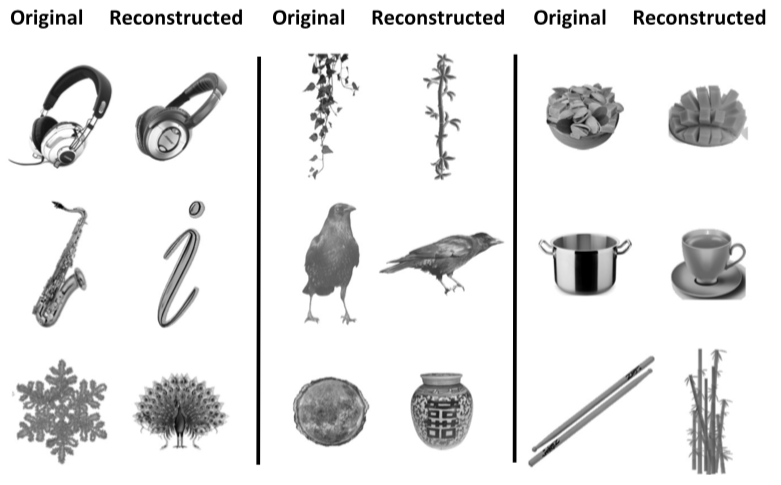
Consistent with a linear code, they were able to find a linear decoder of features from responses, and thereby reconstruct the images that participants were viewing:
In an interesting additional test of the model, they used a GAN trained to produce images from features to generate new images that were farther along the preferred and orthogonal axes than present in their model, and found that responses along those directions behaved as their model predicted.
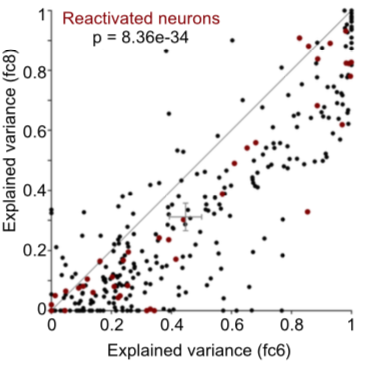
They found that their linear codes best explained the neural responses when they were based on visual features rather than those built on higher level semantic features, for example from later fully-connected layers in AlexNet, or features built from word embeddings:
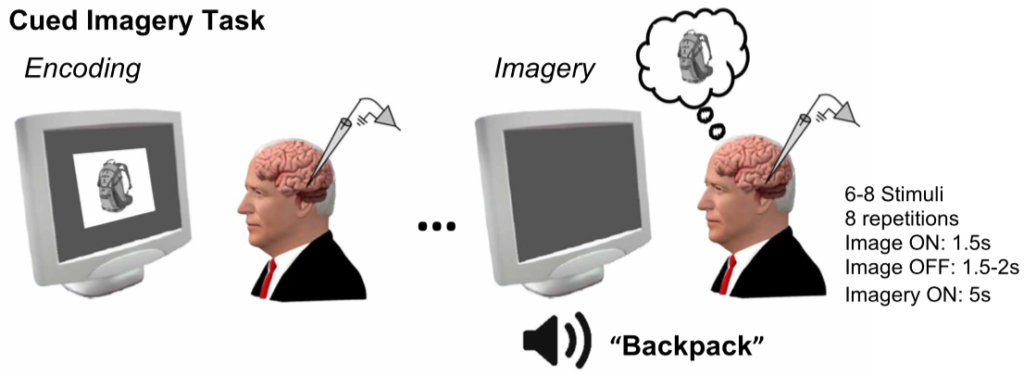
Having established the axis code during the visual perception task, they had a subset of their patients participate in an imagery task, in which they first viewed two of the images in the dataset, then, after a pause, were asked to imagine those images.
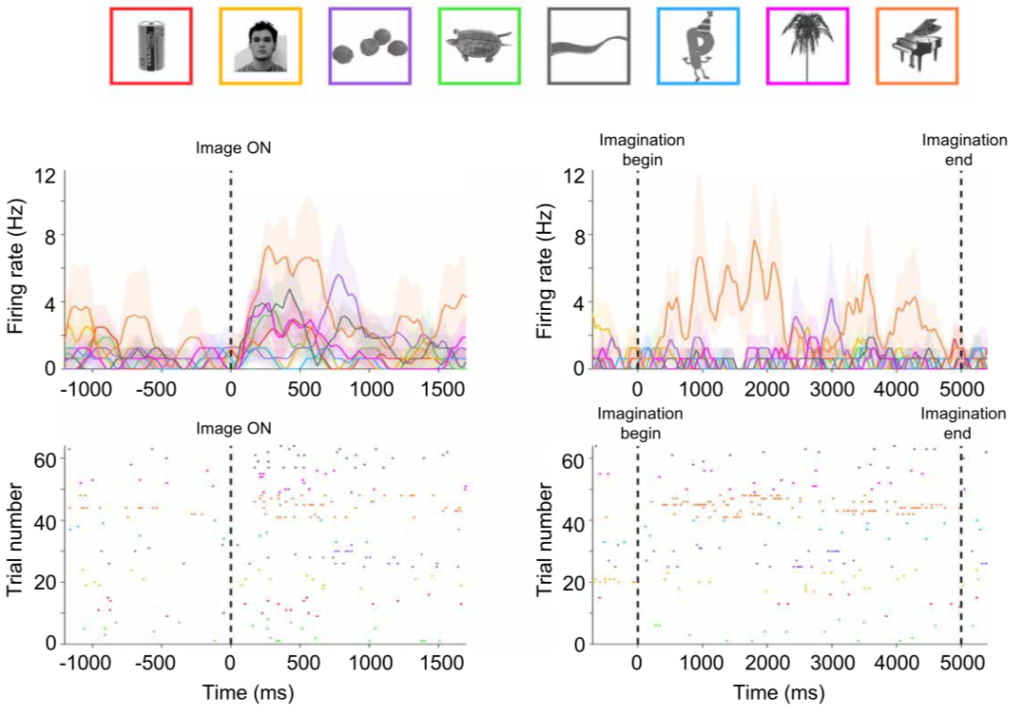
Interestingly, they found ~40% of these neurons respond when participants later imagined the images. Notice how the response of the neuron below to the piano image (orange trace) is high in both the perception (left) and imagery (right) conditions:
The reactivated neurons used a shared code during perception and imagery in two ways. First, decoders signaling which image was present based on the responses could be trained on the perceptual data, and successfully decode the imagery data, indicating the neurons were responding in similar ways in the two conditions:
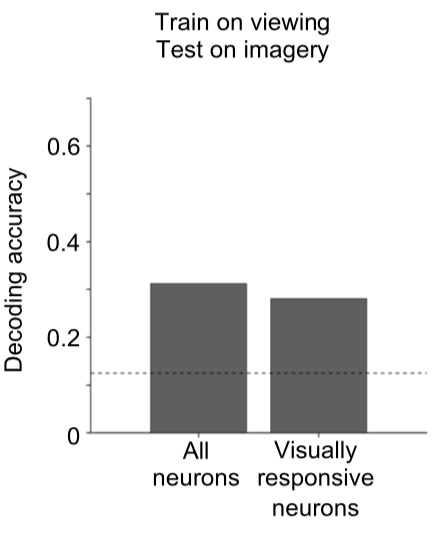
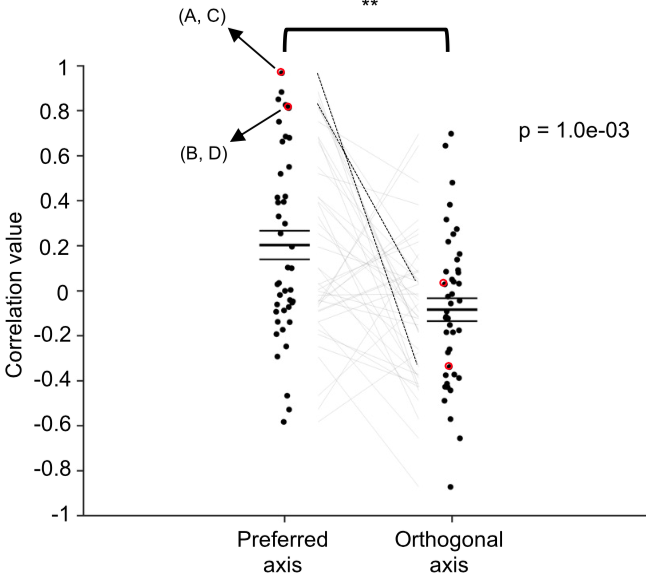
Furthermore, they found the responses in imagery session were correlated with the predictions using the preferred direction found in the perception image, and much less correlated with the orthogonal direction found in those sessions:
Summary
In summary, by recording in humans the authors were able compare neural representations during perception and imagination. They found that neurons in VTC respond to images with a linear “axis” code built on high level, but not semantic, image features, and that a subset of these neurons reactivate during imagery and respond the same way. This shared code of neurons active both during perception and recall would support a generative model for images in the visual system, though much more work needs to be done to establish this, such as direct manipulations of neurons to activate causes while simultaneously recording the effects much farther downstream in the early visual system where the ultimate output of generation, visual imagery, would be.
Comments from the Audience
Audience members raised a number of interesting points I hadn’t considered.
- How do the preferred directions in feature space relate to each other? E.g. are they randomly oriented, or do they tend to be along a specific direction?
- How far along the visual hierarchy are these neurons? This was raised several times in the audience, and I hadn’t considered it. Given (a) the visual features they use and find most effective, (b) the anatomical location of their recordings and (c) the nature of the responses, it seems like their neurons are early in the semantic processing stages – above simple localized visual features, and below specific objects or categories.
- Related to this, another comment was that if the neurons are at such an intermediate position along the hierarchy, then we wouldn’t expect perfect reconstruction. In other words, mistaking a saxophone for the cursive letter ‘i’, as shown in Figure 3C, might be exactly what feature-selective, but not object- ore category-selective neurons, should be doing.
- Is the poor decoding performance when using semantic features (e.g. fc8) vs. visual features (fc6) a consequence of the distributed nature of the latter code, making it more robust to compression with PCA than a sparse, semantic code in e.g. fc8?
- Reality-testing: could some of the “imagery”-only neurons not be signalling pure imagery, but rather simply be imaginging something else? For example, when asked to recall a bus, the patient may recall a different one that those in the dataset, thereby exciting a different set of neurons than responded during the perception phase?
$$\blacksquare$$
Leave a Reply