My notes on Day 2 of Neurips 2025. I wanted to wait till I’d filled more in, but it’s three months later and I think there’s enough here to post!
Rich Sutton “OaK architecture: A vision of super intelligence.”
- Agents are smaller than the world
- Therefore everything they learn is an approximation.
- Therefore the world appears non-stationary
- Agents must be able to learn and act at run-time
- Building in domain-dependent knowledge is ultimately harmful (the bitter lesson)
- Agents should be capable of developing open-ended abstractions.
- General agreement across fields on design components of intelligent agents:
- Perception
- Policy
- Value Function
- Transition Model
- The one-step trap of RL: planning one step ahead
- Errors compound
- Exploration blows up in time.
- Solution: higher-order transition models to plan over larger timescales.
The OaK architecture
- Learning higher-order transitions by constructing reward-respecting subgoals.
- Options and Knowledge
- Option: A tuple of policy (state $\to$ action) and termination function (state $\to [0,1]$ termination)
Concepts and References
- Continual learning
- “Catastrophic loss of plasticity”
- “Reward-respecting sub
Why diffusion models don’t memorize
- Time to generation $\tau_\text{gen}$ is constant.
- Time to memorization increases with number of examples $n$.
- Gap between is good generalization time, early stopping.
Poster Session 1
Generalizable, real-time neural decoding with hybrid state-space models
- Model has three parts:
- Mapping spikes across units and sessions into a common vector state.
- Split time into chunks.
- Learns unit-specific embedding of units.
- Session-specific keys and values queried with a fixed vector.
- Vector state is updated using a state-state model to maintain memory.
- Reading out the predicted behaviour from the history.
- Queried with the session and time.
- Use previous history as keys and values.
- Mapping spikes across units and sessions into a common vector state.
- What is it doing?
- Finding a state-space representation that can be linearly decoded to extract behaviour.
Finding separatrices of dynamical flows with Deep Koopman Eigenfunctions
- Decision making as moving between different basins
- Typical analysis is at the fixed points.
- Found as locations where $\|f(x)\|_2^2 = 0$.
- i.e. zero of a scalar function of the dynamics.
- What such function to find sepratrices?
- Key idea: map dynamics to unstable scalar dynamics $\psi(x)$
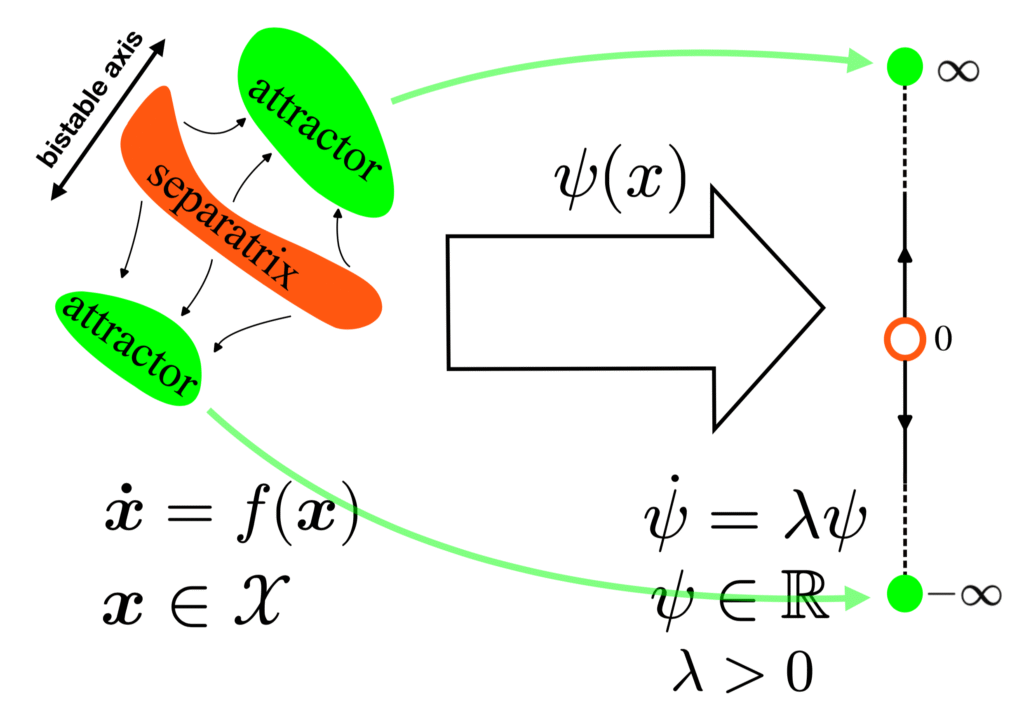
- Zero of the function corresponds to separatrix.
- On either side the function increases to +/- $\infty$: unstable dynamics.
- Use a neural net to find such a function.
- We want $$\dot \psi(x(t)) = \nabla_x \psi^T \dot x = \nabla_x \psi^T f(x) = \lambda \psi,$$ so minimize $$\EE_{x \sim p(x)} \|\nabla \psi ^T f(x) – \lambda \psi \|_2^2.$$
- Do this with a neural net using gradient descent?
- Once you have it, you can design optimal (smallest) perturbations that will move state to the separatrix, evoke new behaviour.
Learning to Cluster Neuronal Function
- Deep learning models can learn per-neuron embeddings that predict responses.
- These embeddings may reflect neuronal types, but don’t cluster.
- If true neuron types cluster, then incorporating this information should improve embeddings.
- Key idea: learn an initial embedding to predict responses, then augment the loss with a clustering promoting term:
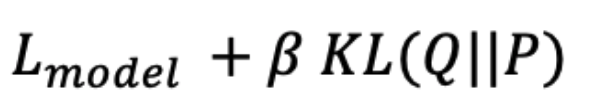
- Here Q is the data distribution, modelled as a mixture of t-distributions
- Number of distributions is a parameter.
- P is a target distribution based on previous work.
- Fit using various numbers of clusters, measure quality of clustering using adjusted rand index.
- Optimize $\beta$ using cross-validation?
- Setting # clusters to whateve maximizes ARI finds the right number of clusters in marmoset.
- No clear peak in ARI in V1, suggests no clear types but rather a continuum.
Johnson-Lindenstrauss Lemma Beyond Euclidean Geometry
- JL lemma: given a set of points in $n$-dimensional Euclidean space, there exists a mapping $f$ to $m$-dimensional Euclidean space that approximately preserves distances, so $(1 – \vareps) \|x_i – x_j\| \le \|f(x_i) – f(x_j)\| \le (1 + \vareps) \|x_i – x_j\|$, where $m$ is $O(\vareps^{-2} \log n).$
- What if only a distance matrix is available, not point coordinates, and what if distance are not necessarily metric (don’t satisfy triangle inequality)?
- Non-metric distances can be expressed as a sum of positive and negative Euclidean part.
- Result: Prove that JL holds for this positive-negative split.
- Non-metric distances can also be expressed as a power distance.
- Result: Prove that JL holds for the power distance.
Spectral Analysis of Representational Similarity with Limited Neurons
Brain-like Variational Inference**
- Introduce FOND: Free Energy Optimization using Natural Gradient Dynamics.
- Their idea is to derive neurally plausible algorithms by iterative minimization of the negative variational free energy.
- This is an old idea.
- They do a concrete demonstration by using a poisson model with log rates
- Show that it outperforms standard methods on sparsity, neural plausibility, etc.
- Show that it outperforms amortized inference methods.
Jacobian-Based Interpretation of Nonlinear Neural Encoding Model
- Metric for measuring nonlinearity by quantifying changes in input-output Jacobian of NN model with input.
- Per voxel, compute input output jacobian per sample.
- Compute the mean across samples
- Compute deviation relative to the mean
- Summarize deviations across coordinates using L1 norm
- Measure the variance of the mean absolute deviations across samples.
Brain-Like Processing Pathways Form in Models With Heterogeneous Experts
Poster Session 2
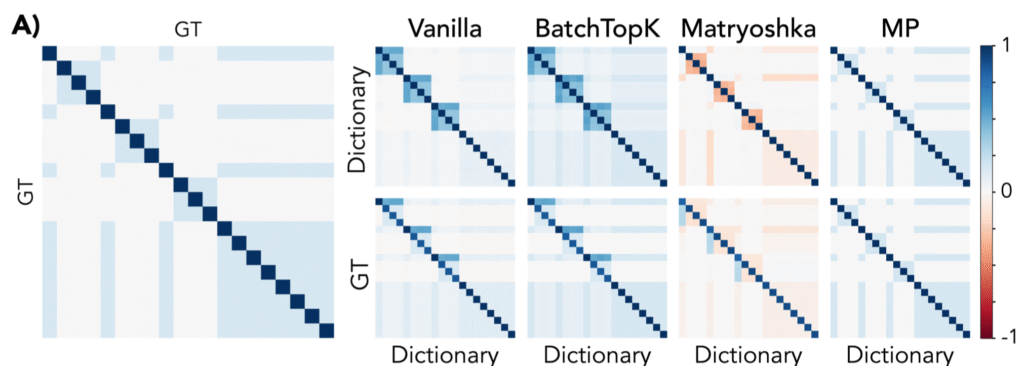
From Flat to Hierarchical: Extracting Sparse Representations with Matching Pursuit
- Sparse auto-encoders are useful for capturing concepts.
- Assume that images are linear combinations of concepts.
- Natural scences have hierarchical structure.
- Deep nets trained on natural scenes uncover hierarchical structure.
- Concepts at different layers tend to be orthogonal.
- Vanilla sparse auto-encoders have trouble capturing this hierarchical structure.
- Solution: replace inference stage of auto-encoder with matching pursuit:
- Iteratively find the concept most correlated with the current residual and subtract it out.
- Has the property that the result residual is orthogonal to the selected concept.
- Naturally captures the cross-hierarchy-layer orthogonality.
- At least for adjacent layers.
- Tested on surrogate data.
- Data has hierarchical structure if $p(parent|child) = 1$ but $p(child|parent) < 1$.
- MP-SAE recovers the underlying dictionary element relationships
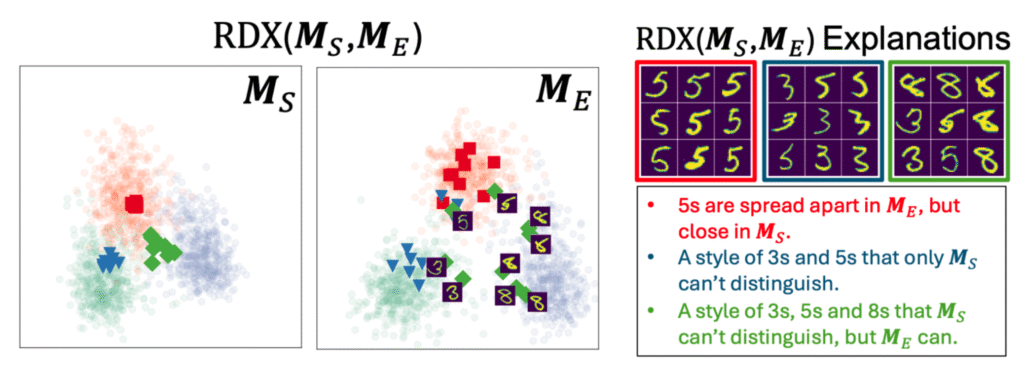
Representational Difference Explanations
- Want to find differences in representation
- Outcome: clustering of samples that are considered similar in one rep but not the other.
- Approach:
- Compute $n \times n$ distance matrices $D_A$ and $D_B$ for the two reps.
- Normalize distance matrices $d_A$ and $d_B$, using nearest neighbours.
- Compute a relative difference of normalized distances: $$G_{A,B}^{ij} = {d_A^{ij} – d_B^{ij} \over \min(d_A^{ij}, d_B^{ij})}.$$
- Compress these to $\{-1,1\}$ using $\tanh$ and form an affinity matrix by passing through negative exponential: $$F_{A,B}^{ij} = \exp(-\beta\tanh(\gamma G_{A,B}^{ij}).$$
- This will produce strong links between pairs that are more similar in $A$ than in $B$.
- Cluster the resulting graph, forming explanations:
- Different configurations of samples that are more similar in $A$ than in $B$.
Connecting Jensen–Shannon and Kullback–Leibler Divergences
Fast exact recovery of noisy matrix from few entries: the infinity norm approach
Leave a Reply