These notes are based on Section 8.2.2 of Bishop’s “Pattern Recognition and Machine Learning.” See my related video below:
When working with a complicated Bayesian network it will often be useful to determine which other nodes a given node of interest depends on. One way to do address this is to consider the conditional distribution of our node, $x_i$, given all others in the network: $$ p(x_i|x_{j \neq i}).$$
An extreme possibility is that our node depends on all the other nodes. However, in many cases the dependency of our node on the rest of the network is only via a subset, $S$, of the nodes. That is, knowledge of that subset determines the value of our node, making it conditionally independent of all the rest: $$ p(x_i | x_{j \neq i} ) = p(x_i | \{x_k, k \in S\}).$$ Such a subset is called a Markov blanket of our node $x_i$. The smallest such subset is called the Markov boundary, although Bishop uses `blanket’ for the boundary as well.
In this post we’ll show how to find the Markov boundary of a node, in two ways. First, we’ll look at a few simple examples that will suggest the answer. Then we’ll confirm this answer by looking at the question more formally.
Examples
The first example we’ll look at is a simple chain:

Say we’re interested in node $c$. Clearly it is dependent on $b$, its parent. It is also dependent on $a$, but only through $b$. So knowledge of $b$ blocks this path of dependence between $a$ and $c$. This would clearly also apply to any other nodes upstream of $a$. Therefore, at least in this graph, knowledge of the parent of $b$ is enough to make $c$ conditionally independent of all nodes upstream of the parent.
Our node $c$ also determines its child $d$, so knowledge of $d$ tells us about $c$. The node $c$ also determines $e$, but only through $d$. So knowledge of $d$ blocks the dependence between $c$ and $e$. Therefore, at least in this graph, knowledge of the child of $c$ is enough to make it conditionally independent of all nodes downstream of that child.
Based on these two observations, we can see that we need to know at least the parents and children of a node to make it conditionally independent of the rest of the nodes in the graph.
These two cases correspond to the “head-to-tail” d-separation criterion for conditional independence. In each case, information about the parent or the child corresponds to an observation of a head-to-tail node along the path from our node of interest to some node outside our observed set. The observation blocks the dependency, yielding conditional independence.
Have we covered all the cases? Let’s consider a general Bayesian network. We can consider starting at some node outside of either the parents and children of our node of interest and following all paths emanating from that node. If a path passes through our node of interest, then it must have passed through one of its parents. Since we assume all our node’s parents are observed, all such dependencies would be blocked. This is an example of the chain case considered above.
What if a path pass through a child of our node of interest? For example, consider the graph below:
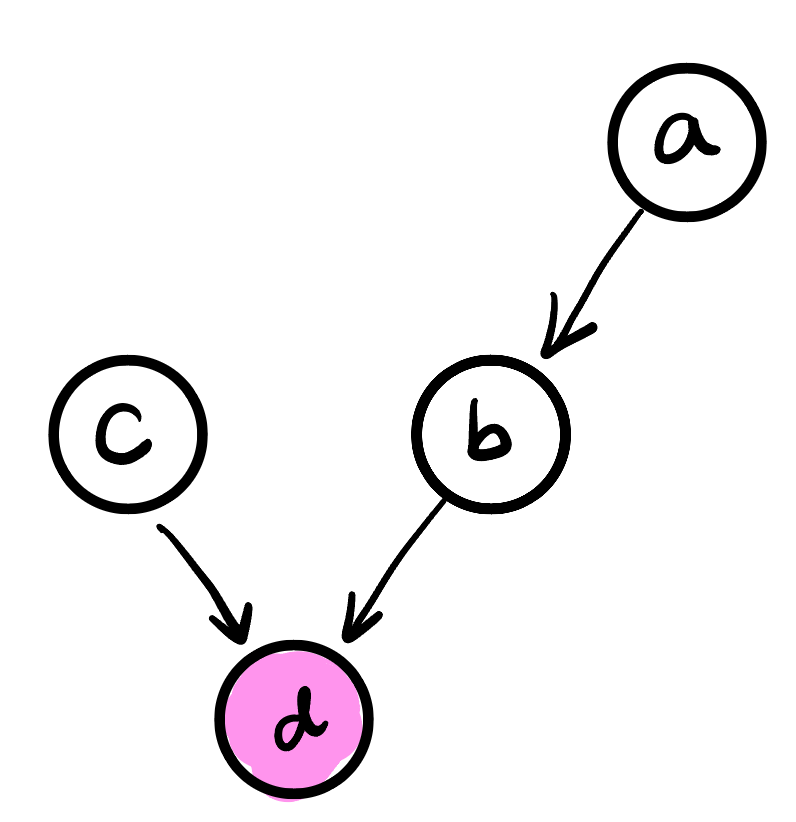
Our observation of the child $d$ induces a dependence between $a$ and $c$, since both $a$ and $c$ “cause” $d$. This is an example of “explaining away”, and corresponds to the d-separation criterion of a dependency path containing an observed “head-to-head” node, $d$ in our case.
However, we can block this dependency by adding $b$ to the observed set. Since any effect of $a$ on $d$ must go through $b$, observing $b$ blocks $a$’s effect on $d$, and hence any dependency observing $d$ would induce between $a$ and $c$:
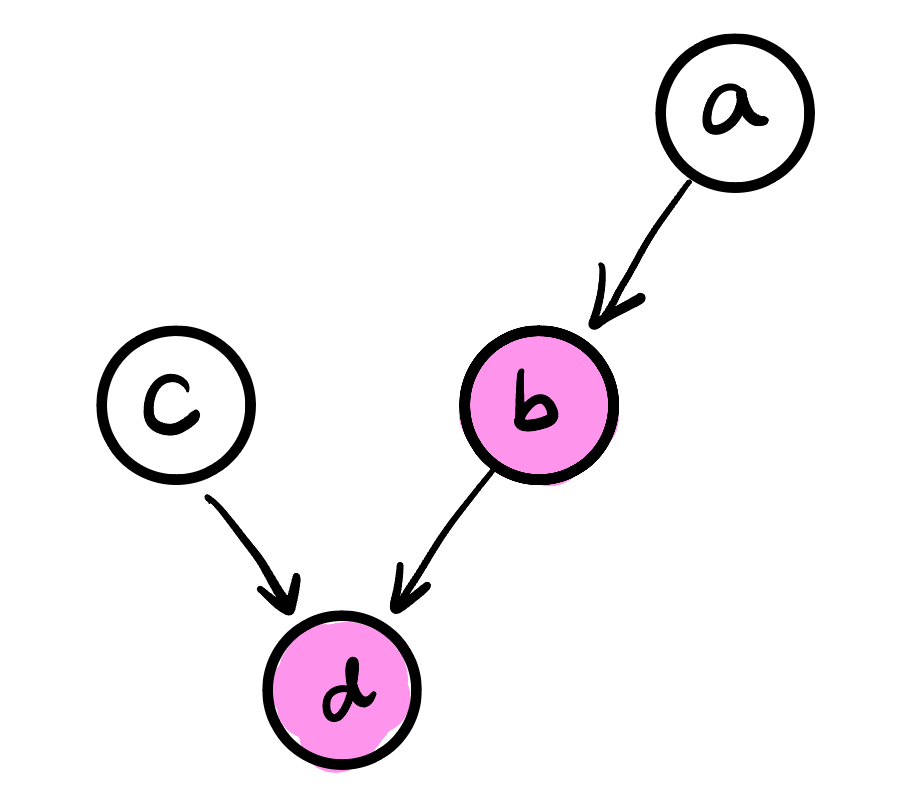
This example shows that we also need to observe any nodes with whom our node of interest is a co-parent. In the example above, $b$ is a co-parent of $d$ with $a$, and therefore we need to add it to the observed list, to make $c$ conditionally independent of $a$.
The only remaining possibility is for a path from our external node $a$ to land on a node that is a child of one of the children of our node of interest:
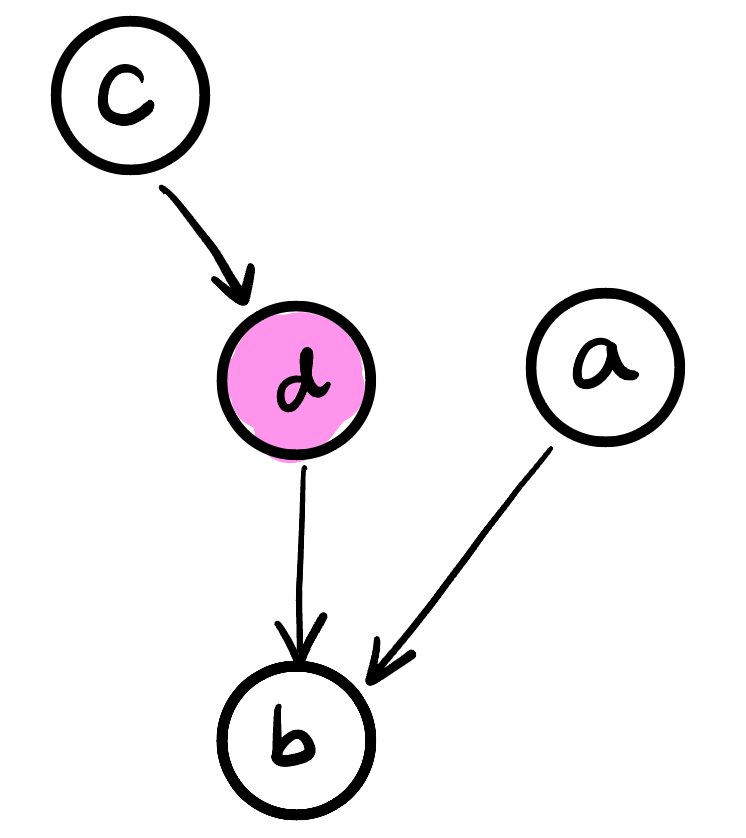
But any dependence of $c$ on $a$ through $b$ must pass through $d$, which is observed, and $c$ and $a$ remain conditionally independent.
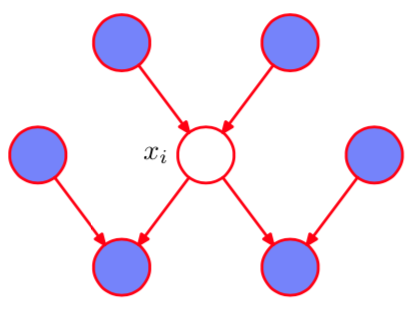
To summarize, the set of nodes we need to observe to make a node of interest conditionally independent of all others in the graph are the node’s parents, children, and co-parents.
A formal derivation
We can also come to the conclusion above formally. Let’s consider a graph formed of $D$ nodes, and consider conditioning one, $x_i$, on all others: \begin{align*} p(x_i | x_{\{j \neq i\}}) &= { p(x_1, \dots, x_D) \over p(x_1, \dots, x_{i-1}, x_{i+1}, \dots, x_D) }\\ &= { \prod_{k=1}^D p(x_k | \text{pa}_k) \over \int \prod_{k=1}^D p(x_k | \text{pa}_k) dx_i }\end{align*}
Now when evaluating the integral in the denominator that marginalizes out $x_i$, any terms that don’t contain $x_i$ anywhere can be taken out of the integral. These are the terms for which $x_i$ is neither the variable of interest, so $i \neq k$, nor in the conditioning set, so $i \not \in \text{pa}_k$. Thus, $$ \int \prod_{k=1}^D p(x_k | \text{pa}_k) dx_i = \left[\prod_{k: i \not \in \{k\} \cup \text{pa}_k} p(x_k| \text{pa}_k)\right] \int p(x_i|\text{pa}_i) \prod_{k: i \in \text{pa}_k} p(x_k | \text{pa}_k) \; dx_i.$$
The terms we pulled out of the integral also appear in the numerator, so cancel: \begin{align*} p(x_i | x_{j \neq i}) &= { \left[\prod_{i \not \in \{k\} \cup \text{pa}_k} p(x_k| \text{pa}_k) \right] p(x_i|\text{pa}_i) \prod_{k: i \in \text{pa}_k} p(x_k | \text{pa}_k) \over \left[\prod_{i \not \in \{k\} \cup \text{pa}_k} p(x_k| \text{pa}_k)\right] \int p(x_i|\text{pa}_i) \prod_{k: i \in \text{pa}_k} p(x_k | \text{pa}_k) \; dx_i} \\ &= {p(x_i|\text{pa}_i) \prod_{k: i \in \text{pa}_k} p(x_k | \text{pa}_k) \over \int p(x_i|\text{pa}_i) \prod_{k: i \in \text{pa}_k} p(x_k | \text{pa}_k) \; dx_i}.\end{align*}
Examining this expression shows that there are only three types of nodes in the graph that $x_i$ depends on:
- Its parents, contributed by the $\text{pa}_i$ term,
- Its children, contributed by each $x_k$ in the $p(x_k|\text{pa}_k)$ term,
- Its co-parents, contributed by nodes other than $i$ in $\text{pa}_k$ for each $p(x_k|\text{pa}_k)$ term,
confirming our earlier conclusion.
$$ \blacksquare $$
Leave a Reply