We’re going to try to make sense of the solutions to minimizing the following $$L(\zz) = {1 \over 2} \|\XX^T \ZZ^T \JJ \ZZ \XX – \SS\|_F^2 + {\lambda \over 2}\|\zz – \bone\|_2^2, \quad \ZZ = \diag(\zz), \quad \JJ = \II – N^{-1} \bone \bone^T = \II -\II \II$$
The differential is $$ dL = \tr(\bE^T (\XX^T d\ZZ^T \JJ \ZZ \XX + \XX^T \ZZ^T \JJ d\ZZ \XX)) + \lambda (\zz – \bone)^T d\zz$$ so, using that $\bE$ is symmetric, the gradient is $$ \nabla L = 2 \diag(\JJ \ZZ \XX \bE \XX^T) + {\lambda} (\zz – \bone).$$
Expanding out the the first term, we have \begin{align*} \diag(\JJ \ZZ \XX\bE \XX^T) &= \diag(\JJ \ZZ \XX (\XX^T \ZZ^T \JJ \ZZ \XX – \SS)\XX^T) \\ &= \diag(\JJ \ZZ \XX \XX^T \ZZ^T \JJ \ZZ \XX\XX^T) – \diag(\JJ \ZZ \XX \SS \XX^T). \end{align*}
Expand the $\JJ$ in the first term we get \begin{align} \diag((\II – \II\II)\ZZ\XX \XX^T \ZZ^T (\II – \II \II) \ZZ \XX\XX^T) &= \diag(\ZZ \XX \XX^T \ZZ^T \ZZ \XX \XX^T)\\ &- \diag(\II\II \ZZ \XX\XX^T \ZZ^T \ZZ \XX \XX^T)\\ &- \diag(\ZZ \XX \XX^T \ZZ^T \II \II \ZZ \XX \XX^T) \\ &+ \diag(\II\II \ZZ \XX \XX^T \ZZ^T \II \II \ZZ \XX \XX^T).\end{align}
Because $\ZZ$ is diagonal, the first term simplifies: \begin{align*}\diag(\ZZ \XX \XX^T \ZZ^T \ZZ \XX \XX^T) &= \ZZ \diag( \XX \XX^T \diag(\zz^2) \XX \XX^T) \\ &= \ZZ \, (\XX \XX^T \odot \XX \XX^T) \zz^2.\end{align*}
For the second term, note that $\diag(\bone \aa^T) = \aa.$ So, \begin{align*} \diag(\II\II \ZZ \XX\XX^T \ZZ^T \ZZ \XX \XX^T) &= N^{-1} \XX \XX^T \diag(\zz^2) \XX\XX^T \zz. \end{align*}
For the third term, note that $\diag(\aa \aa^T) = \aa^2.$ So, \begin{align*}\diag(\ZZ \XX \XX^T \ZZ^T \II \II \ZZ \XX \XX^T) = N^{-1} \ZZ (\XX \XX^T \zz)^2.\end{align*}
Finally, for the fourth term, we have \begin{align*} \diag(\II\II \ZZ \XX \XX^T \ZZ^T \II \II \ZZ \XX \XX^T) &= N^{-2} \XX \XX^T \zz \zz^T \XX \XX^T \zz. \end{align*}
Similarly, $$ \diag(\JJ \ZZ \XX \SS \XX^T) = \ZZ \diag(\XX \SS \XX^T) – N^{-1} \XX \SS \XX^T \zz.$$
Putting these all together, gives: \begin{align*} {1 \over 2} \nabla L &= \diag(\JJ \ZZ \XX \bE \XX^T)+ {1 \over 2} \lambda (\zz – 1)\\ &= \diag(\JJ \ZZ \XX \XX^T \ZZ^T \JJ \ZZ \XX\XX^T) – \diag(\JJ \ZZ \XX \SS \XX^T) + {1 \over 2}\lambda (\zz – 1)\\ &= \ZZ \, (\XX \XX^T \odot \XX \XX^T) \zz^2 – \ZZ \diag(\XX \SS \XX^T)\\&- N^{-1} \XX \XX^T \diag(\zz^2) \XX\XX^T \zz\\ &- N^{-1} \ZZ (\XX \XX^T \zz)^2\\ &+N^{-1} \XX \SS \XX^T \zz\\ &+ {\zz^T \XX \XX^T \zz \over N^2} \XX \XX^T \zz\\ &+ {1 \over 2}\lambda (\zz – 1) . \quad \checkmark\end{align*}
For the value of $\lambda$ that we’re using (around 50k), all of these components, except for the $N^{-2}$ one, are empirically quite large. So we need to incorporate all of them.
Trying to solve this for $\zz$ is hopeless, and probably wouldn’t be very meaningful anyway. The approach we took before was to look at the gradient of a single element, and split it into components from that element and all others.
Let $\CC \triangleq \XX \XX^T$. Then \begin{align*}[\ZZ (\CC \odot \CC) \zz^2]_i &= z_i \sum_j C^2_{ij} z_j^2 =C^2_{ii} z_i^3 + z_i \sum_{j\neq i} C^2_{ij}z_j^2\\ [\ZZ \diag(\XX \SS \XX^T)]_i &= z_i \sum_{j} X_{ij}^2 S_j.\end{align*}
Next, \begin{align*} [\CC \diag(\zz^2) \CC \zz]_i &= \sum_{j,k} C_{ij} z_j^2 C_{jk} z_k \\ &= \underbrace{C_{ii}^2 z_i^3}_{j = i = k}+\underbrace{C_{ii} z_i^2 \sum_{k \neq i} C_{ik} z_k}_{j = i \neq k} + \underbrace{z_i\sum_{j \neq i} C_{ij}^2 z_j^2}_{j \neq i = k} + \underbrace{\sum_{j,k \neq i} C_{ij} C_{jk} z_j^2 z_k}_{j \neq i \neq k}. \checkmark \end{align*}
Next, \begin{align*} [\ZZ (\CC \zz)^2]_i &= z_i\left[ \sum_j C_{ij} z_j \right]^2 = z_i (C_{ii}z_i + \sum_{j \neq i} C_{ij} z_j)^2 \\ &= z_i (C_{ii}^2 z_i^2 + 2 C_{ii} z_i \sum_{j \neq i} C_{ij} z_j + \sum_{j, k \neq i} C_{ij} C_{ik} z_j z_k) \\ &= C_{ii}^2 z_i^3 + 2 C_{ii} z_i^2 \sum_{j \neq i} C_{ij} z_k + z_i \sum_{j,k \neq i} C_{ij} C_{ik} z_j z_k. \checkmark \end{align*}
To understand how to deal with the new terms related to the mean-subtraction, let’s first look at what our original approach looked like in these terms.
We didn’t try to solve these equations, rather we looked at how the values of each gain were determined by what was going on in the rest of the network.
The relevant gradient equation there was $$ 0 = {1 \over 2} [\nabla L]_i = {\lambda \over 2}(z_i – 1) + C_{ii}^2 z_i^3 + z_i \sum_{j \neq i} C_{ij}^2 z_j^2 – z_i \sum_\mu X_{i\mu}^2 s_\mu.$$
We rearranged this into the equation $$ z_i^3 =z_i {\sum_\mu X_{i\mu}^2 s_\mu – \sum_{j \neq i} C_{ij}^2 z_j^2 – {\lambda \over 2} \over C_{ii}^2} + {\lambda \over 2 C_{ii}^2}.$$
We then expressed this in terms of the atomic representations contributed by each unit, $$ \rr_i \triangleq [r_{i, \alpha \beta}], \quad r_{i,\alpha\beta} = X_{i\alpha} X_{i\beta}.$$
In these terms, $$C_{ii}^2 = (\sum_\alpha X_{i\alpha}^2)^2 = \sum_{\alpha, \beta} X_{i\alpha}^2X_{i,\beta}^2 = \sum_{\alpha,\beta} (X_{i\alpha} X_{i\beta})^2 = \sum_{\alpha,\beta} r_{i,\alpha \beta}^2 = \|\rr_i\|_2^2.$$
Similarly, $$ C_{ij}^2 = (\sum_\alpha X_{i\alpha} X_{j\alpha})^2 = \sum_{\alpha\beta} X_{i\alpha} X_{j\alpha} X_{i\beta} X_{j\beta} = \sum_{\alpha\beta} (X_{i\alpha} X_{i\beta})(X_{j\alpha} X_{j\beta}) = \sum_{\alpha\beta} r_{i, \alpha\beta} r_{j,\alpha\beta} = \rr_i^T \rr_j.$$
Finally, if we defined $\ss = \vec{\diag(s_\mu)}$, then $$\sum_\mu X_{i\mu}^2 s_\mu = \sum_{\mu \nu} X_{i \mu} X_{i\nu} s_{\mu\nu} = \sum_{\mu \nu} r_{i, \mu\nu} s_{\mu\nu} = \rr_i^T \ss.$$
We could then write $$ z_i^3 = z_i {\rr_i^T \ss – \sum_{j \neq i} \rr_i^T \rr_j z_j^2 – {\lambda \over 2} \over \|\rr_i\|_2^2} + {\lambda \over 2 \|\rr_i\|_2^2}.$$
Now $$ \ss_i \triangleq \sum_{j \neq i} \rr_j z_j^2$$ was the prediction contributed by all other units. So, defining $$ \lambda_i \triangleq {\lambda \over 2 \|\rr_i\|_2^2},$$ we arrived at $$ z_i^3 = z_i {(\ss -\ss_i)^T \hat \rr_i – \lambda_i \over \|\rr_i\|} + {\lambda_i \over \|\rr_i\|}.$$
Let’s now see if we can express the new terms in the same way.
The first one is, $$C_{ii} C_{ik} = (\sum_\alpha X_{i\alpha}^2) (\sum_\beta X_{i\beta} X_{k\beta}) = \sum_{\alpha \beta} X_{i\alpha}^2 X_{i\beta} X_{k\beta} = \sum_{\alpha \beta} (X_{i\alpha} X_{i\beta}) (X_{i\alpha} X_{k \beta}) \triangleq \rr_i^T \rr_{ik},$$ where we’ve implicitly defined the atom of the cross-represntation as $\rr_{ik}$
We also have $$ C_{ik} C_{jk} = (\sum_\alpha X_{i\alpha} X_{k \alpha}) (\sum_\beta X_{j \beta} X_{k\beta}) = \sum_{\alpha \beta} X_{i\alpha} X_{k\alpha} X_{j\beta} X_{k\beta} = \sum_{\alpha \beta} (X_{i\alpha} X_{j\beta}) (X_{k\alpha} X_{k\beta}) = \rr_{ij}^T \rr_{k}.$$
Finally $$ C_{ij} C_{jk} = (\sum_\alpha X_{i\alpha} X_{j \alpha}) (\sum_\beta X_{j \beta} X_{k\beta}) = \sum_{\alpha \beta} X_{i\alpha} X_{j \beta} X_{j\alpha} X_{k\beta} = \sum_{\alpha \beta} (X_{i\alpha} X_{j \beta}) (X_{j\alpha} X_{k\beta}) = \rr_{ij}^T \rr_{jk} = \rr_{ik}^T \rr_j.$$
In general, $$ C_{ij} C_{mn} = \rr_{im}^T \rr_{jn} = \rr_{in}^T \rr_{jm}.$$
With these definitions in hand, we can return to our original expressions.
The first is \begin{align*} [\CC \diag(\zz^2) \CC \zz]_i &= C_{ii}^2 z_i^3 + C_{ii} z_i^2 \sum_{k \neq i} C_{ik} z_k + z_i\sum_{j \neq i} C_{ij}^2 z_j^2 + \sum_{j,k \neq i} C_{ij} C_{jk} z_j^2 z_k \\ &= \rr_i^T \rr_i z_i^3 + z_i^2 \sum_{k \neq i} z_k \rr_i^T \rr_{ik} + z_i \sum_{j \neq i} \rr_i^T \rr_j z_j^2 + \sum_{j,k \neq i} \rr_{ij}^T \rr_{jk} z_j^2 z_k\\ &= \|\rr_i\|_2^2 z_i^3 + z_i^2 \rr_i^T \sum_{j \neq i} \rr_{ij} z_j + z_i \rr_i^T \sum_{j \neq i} \rr_j z_j^2 + \sum_{j,k \neq i} \rr_{ij}^T \rr_{jk} z_j^2 z_k. \checkmark\end{align*}
The second is \begin{align*} [\ZZ (\CC \zz)^2]_i &= C_{ii}^2 z_i^3 + 2 C_{ii} z_i^2 \sum_{j \neq i} C_{ij} z_j + z_i \sum_{j,k \neq i} C_{ij} C_{ik} z_j z_k\\ &=\|\rr_i\|_2^2 z_i^3 + 2 z_i^2 \rr_i^T \sum_{j \neq i} \rr_{ij} z_j + z_i \rr_i^T\sum_{j,k\neq i} \rr_{jk} z_j z_k. \checkmark \end{align*}
We also have \begin{align*}[\XX \SS \XX^T \zz]_i &= \sum_{\alpha,j} X_{i\alpha} s_\alpha X_{j \alpha} z_j = \sum_{\alpha \beta, j} X_{i \alpha} X_{j \beta} s_{\alpha \beta} z_j = \sum_{\alpha\beta,j} r_{ij, \alpha \beta} s_{\alpha \beta} z_j = \ss^T \sum_j \rr_{ij} z_j.\checkmark\end{align*}
It may also be useful to see what the prediction is in these terms. \begin{align*} [\XX^T \ZZ^T \JJ \ZZ \XX]_{\alpha\beta} &= [\XX^T \ZZ^2 \XX – N^{-1}\XX^T \zz \zz^T \XX]_{\alpha\beta} \\ &= \sum_i X_{i \alpha} z^2_i X_{i \beta} – N^{-1}(\sum_i X_{i \alpha} z_i )(\sum_i X_{i\beta} z_i) \\ &= \sum_i X_{i \alpha} X_{i \beta}z^2_i – N^{-1} \sum_{ij} X_{i \alpha} X_{j \beta} z_i z_j \\ &= \left[\sum_i \rr_i z_i^2 – {1 \over N} \sum_{ij} \rr_{ij} z_i z_j\right]_{\alpha \beta}.\checkmark\end{align*}
Let’s now tabulate the terms: $$\begin{array}{|c|c|c|} \hline \textbf{Term} & \textbf{Expression} \\ \hline \ZZ (\CC \odot \CC) \zz^2 & \|\rr_i\|_2^2 z_i^3 + z_i \sum_j \rr_i^T \rr_j z_j^2 \\ -\ZZ \diag(\XX \SS \XX^T) & -z_i \rr_i^T \ss \\ -{1 \over N} \CC\diag(\zz^2) \CC^T \zz & -{1 \over N} (\|\rr_i\|_2^2 z_i^3 + z_i^2 \rr_i^T \sum_{j \neq i} \rr_{ij} z_j + z_i \rr_i^T \sum_{j \neq i} \rr_j z_j^2 + \sum_{j,k \neq i} \rr_{ij}^T \rr_{jk} z_j^2 z_k) \\ -{1 \over N} \ZZ (\CC \zz)^2 & – {1 \over N} ( \|\rr_i\|_2^2 z_i^3 + 2 z_i^2 \rr_i^T \sum_{j \neq i} \rr_{ij} z_j + z_i \rr_i^T \sum_{j,k\neq i} \rr_{jk} z_j z_k)\\ {1 \over N} \XX \SS \XX^T \zz & { 1 \over N} \ss^T \sum_j \rr_{ij} z_j \\ {\zz^T \CC \zz \over N^2} \CC \zz & \approx 0 \\ {1 \over 2} \lambda(\zz – 1) & \\ \hline \end{array} .$$
We can plot the absolute value of each component of the gradient,
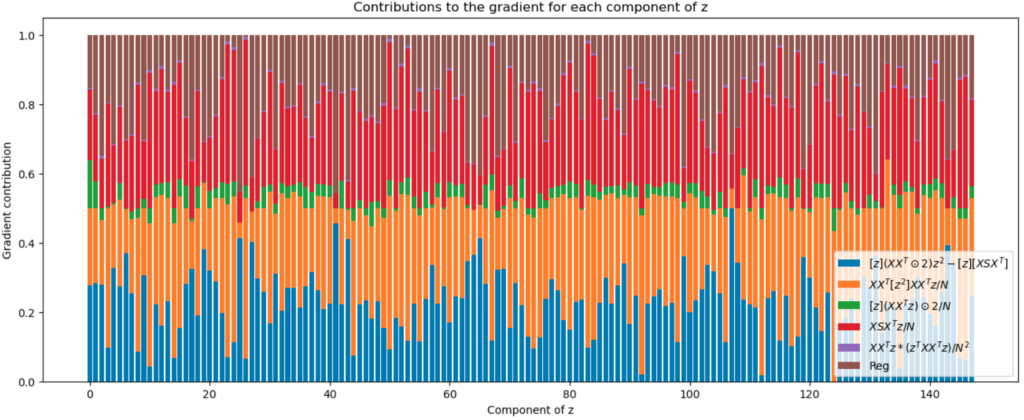
The big contributions due to averaging come from the orange term and the red term. It’s curious that the green term is so much smaller than the red one, even though they’re so similar in their constitutions.
The orange term is $$ [\CC [\zz^2] \CC \zz]_i = \sum_{jk} C_{ij} C_{jk} z_j^2 z_k = \sum_{jk} \rr_{ij}^T \rr_{jk} z_j^2 z_k.$$
We can split this up further into: \begin{align*} \rr_{ii}^T \rr_{ii} z_i^3 =& \|\rr_i\|_2^2 z_i^3 & (j = k = i) \\ &\sum_{\substack{k \neq j \\ j = i}} \rr_{ii}^T \rr_{ik} z_i^2 z_k & (j = i \neq k) \\ \sum_j \rr_{ij}^T \rr_{ji} z_j^2 z_i = &\sum_{\substack{j \neq k\\ k = i}} \rr_{ij}^T \rr_{ji} z_j^2 z_i & (j \neq k = i )\\ & \sum_{j = k \neq i} \rr_{ij}^T \rr_{jj} z_j^3 & (j = k \neq i)\\ & \sum_{\substack{j \neq k\\ j \neq i\\ k \neq i}} \rr_{ij}^T \rr_{jk} z_j^2 z_k & (j \neq k, j\neq i) \end{align*}
Most of the contribution is coming from the last term:
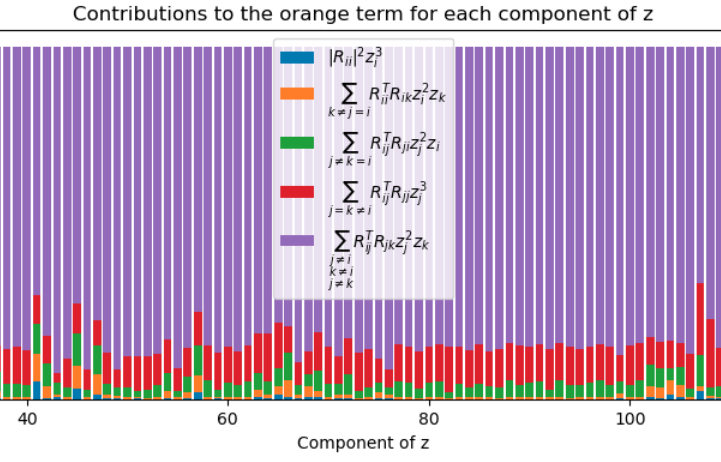
The last two terms are the ones that don’t involve $i$, and combining them accounts for most of the orange term.
But the plot above is the relative contributions to each term. In terms of the absolute level of variation, there is a lot:
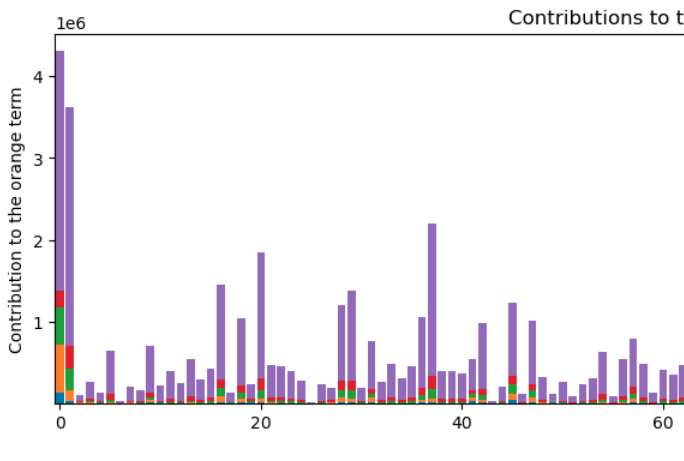
Hmm…
We can also collect the gradient terms into various groups: \begin{align} {1 \over 2} [\nabla L]_i &= (1 – {2 \over N}) \|\rr_i\|_2^2 z_i^3\\ &-\ss^T (\rr_i z_i – {1 \over N} \sum_j \rr_{ij} z_j) \\ &+z_i \rr_i^T (\RR \zz^2 – {1 \over N}\RR_{/i} \zz_{/i}^2) \\ &-{1 \over N} \sum_{j,k\neq i}(z_i \rr_{ii} + z_j \rr_{ij})^T \rr_{jk} z_j z_k\\ &+{1\over 2} \lambda (\zz – 1). \end{align}
I wonder if organizing into representations like I have above is the right way to go. Perhaps there’s a more appropriate coordinate system that will help collect the variability?
Leave a Reply