My notes on Day 3 of NeurIPS 2025. Wanted to wait till when they were more polished, but after three months I’m just posting as is.
Poster Session 3
Seemingly Redundant Modules Enhance Robust Odor Learning in Fruit Flies
- Asks whether spike-frequency adaptation and lateral inhibition in the fly olfactory system are redundant or complementary
- Tests a baseline model (no SFA or LI), against models with just one, and the full model
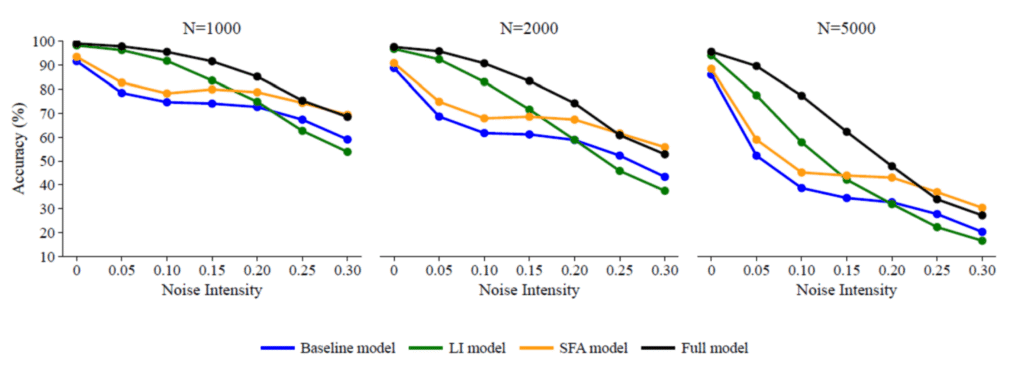
- SFA and LI are better than each other depending on injected noise.
- Full model performs best across all noise conditions:
Neurons as Detectors of Coherent Sets in Sensory Dynamics
- Coherent sets: subsets of state-space that move together in time.
- Neurons, brains want to find representations that track such states.
- Koopman operator: Linear operator in high-dimensional space that reports future state of an observable.
- Linearity means we can write it as $$K_\tau = \sum_{i=0} ^\infty e^{\lambda_i \tau} u_i v_i^T.$$
- Maximize P(f(X(t+\tau)) \in B | f(X(t)) \in A) + P(f(X(t+\tau)) \in B^c | f(X(t)) \in A^c)
- Use the observable that
- TBC
BrainFlow: A Holistic Pathway of Dynamic Neural System on Manifold
- The problem: linking structural connectivity and functional connectivity.
- Both connectivities live on the manifold of symmetric, positive-definite matrices (SPD).
- Can link them using flows along geodesics on the manifold.
- The same structural connectivity will lead to different functional connectivities during different tasks.
- Conversely, functional connectivity produced in different tasks should lead back to the same structural connectivity.
- Problem: Computing flows on the SPD manifold is computationally expensive.
- PSD manifold can be linked to the manifold of lower triangular matrices by the Cholesky decomposition.
- Recent work shows computation on the Cholesky manifold is much easier.
- Solution: Leveraged this recent work to compute flows linking structure and function on the cholesky manifold.
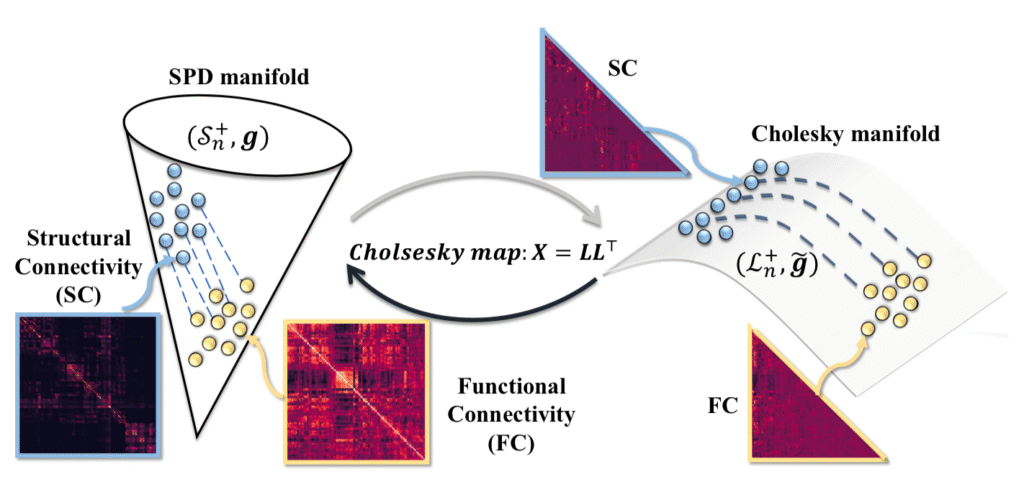
- To get flows from different FC back to the same SC, they add a term that penalizes differences in the Cholesky manifold states.
Dimensionality Mismatch Between Brains and Artificial Neural Networks
- Measured dimensionality of representations across layers in both humans (fMRI data) and ANNs.
- Use both linear dimensionality (participation ratio) and non-linear dimensionality, defined as below.
- As a side note, see Mackay and Gharamani’s note on this estimator.

- The authors found that in humans both measures increase as one moves from V1 towards ventral stream.
- In ANNs, intrinsic dimensionality seems to peak at intermediate layers.
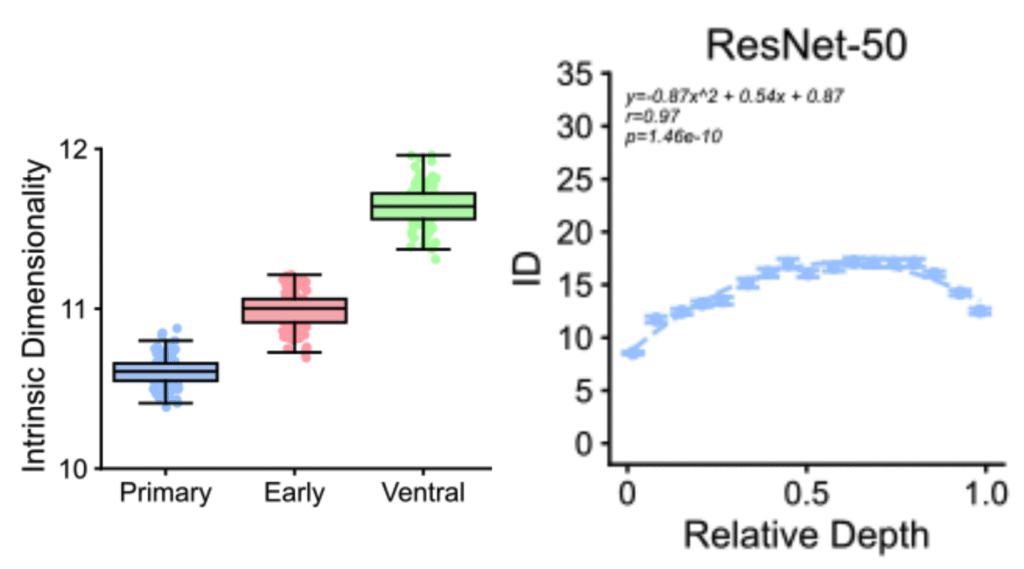
- Suggests that deep-layers in ANN may be compressing their representations, losing abstraction ability.
- Though interestingly the peak still happens at a higher value than in humans.
Modeling Neural Activity with Conditionally Linear Dynamical Systems
- Model nonlinear dynamics as linear conditioned on inputs:
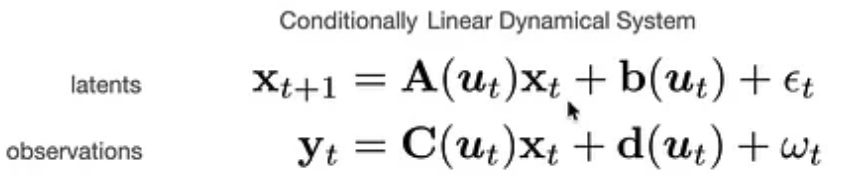
- Notice how inputs modify the parameters, instead of coming in as the usual additive $Bu_t$ terms.
- GP priors on each element of $\mathbf{A, b, C, d}$.
- Get all the benefits of linear systems for inference, prediction etc.
- Can learn parameters with EM:
- E-step: Use current parameter estimates to infer latent states.
- M-step: Solve for parameters by finding coefficients in fixed GP basis.
- Closed form when assuming Gaussian noise.
- Can be seen as conditions specific linearizations of the dynamics.
- Temporal correlation of GP prior can be tuned to capture interesting limits:
- When time constants are small, learns independent, per-condition dynamics.
- When time constants are infinite, fits a fixed, time-invariant linear dynamics (the classical case).
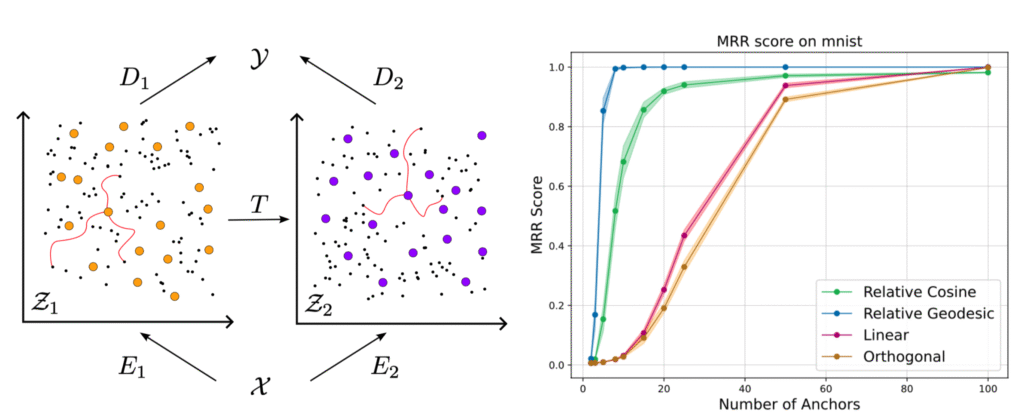
Connecting Neural Models Latent Geometries with Relative Geodesic Representations
- Neural networks (e.g. autoencoders) trained on different samples of the same data often learn similar internal representations.
- These can often be aligned with simple linear transformations.
- Suggests that the same underlying manifold is being parameterized.
- One canonicalization is to not represent the latents in absolute terms, but in relative terms using distances to certain anchor points.
- Previously this has been done using cosine similarity.
- This work: the decoder implicitly defines a pullback metric on the latent space.
- Instead of cosine distance, use geodesic distance defined by this metric.
Leave a Reply